令和4年度長寿科学研究者支援事業 指定課題研究実績報告
本事業は、「認知症発症予防介入戦略拠点の構築のための研究」の第1段階として、認知症の全体像の把握を可能にするためのデータベースを構築することを目的とします。
指定課題研究名
認知症におけるデータベース構築手法の研究
研究代表者
- 所属・職名:国立長寿医療研究センター研究所 研究推進基盤センター長
- 氏名:新飯田 俊平
研究期間
令和3年度~令和5年度(3年計画2年目)
助成金(実績総額)
56,139,632円
研究活動の概要
本研究開発課題では、国立長寿医療研究センター(NCGG)が保有する認知症に関連する情報(データ)資源を集約し、研究に利活用できる統合データベース(iDDR: integrated Database for Dementia Research)を構築することを目的としている。データリソースの対象者は、臨床データ等の研究利用に同意をしているNCGGバイオバンク登録者とした。基盤となる主要なハードウエアはメディカルゲノムセンター(MGC)が構築しているMGCデータサーバーを活用する。
iDDRはバイオバンク・カタログデータベースに紐づく研究用データベースで、共有されるデータ群は、バイオバンク・カタログ情報、心理テストを含む高齢者総合的機能評価(CGA)データ、MRやSPECT等の脳画像データ、ゲノム等のオミクス(Omics)データとした。それぞれのデータは、それぞれの取り扱い部署で、専門家等によるデータクリーニングを実施した。
CGAデータについては、軽度認知障害(MCI)者の縦断的データのクリーニングを先行して行い、ついでアルツハイマー病(AD)症例のクリーニングに移行した。脳画像データについては、コロナ禍とロシア・ウクライナ戦争の影響による半導体不足で、iDDRへのデータ転送システムに必要な部品調達ができず、システム導入が年度末にずれ込んだこと,匿名化システムをカスタマイズする必要があることが分かったことなどから、データ格納は次年度に行うこととした。オミクスデータについては、認知症例の全ゲノム配列(WGS)データ、全ゲノムジェノタイピングデータ(SNP array data)、メッセンジャーRNA(mRNA)発現データのクオリティーチェック(QC)を行った。
データベース のハード・ソフトの構築については、収集したCGAの実データを用いたiDDRのユーザーインターフェイス・プロトタイプの作製を行った。格納データは、ハイパーリンク機能で関連する情報同士を結びつけて情報を整理することが得意なhtml(HyperText Markup Language)コードで閲覧できる仕組みを採用した。今後は画像データの収集も見込まれることから、さらに改良を加える予定である。
研究の成果
本研究開発課題では、NCGGバイオバンクに登録された認知症例のデータを集約し、統合解析などが可能となるリレーショナルデータベース(iDDR)の構築を目指している。iDDRでは、バイオバンクIDをキーとして、CGAデータ、脳画像データ、オミクス(Omics)データを関連付け、表示できるようにプログラミングを進めた。
格納する各種データ群のクリーニング(標準化を含む)は、オリジナルデータを保有する診療科で実施し、ハードディスクに入れた形でMGCに持ち込む方法で進めた(図1)。
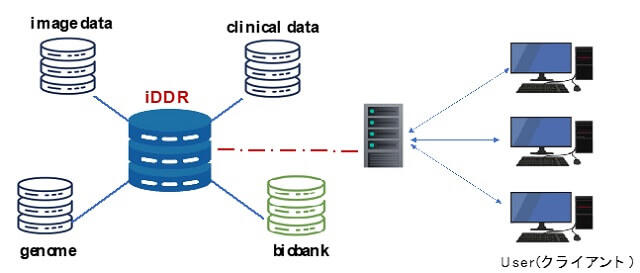
もの忘れセンターでは、バイオバンクに登録されている約1,700例のMCI症例のうち複数回受診のある711症例についてデータクリーニング・標準化を先行させ、その後、AD症例(951例)についても着手し、当該年度は1,173例をiDDRに格納できた。初年度分を合わせると、累計で1,662症例となった(表1)。
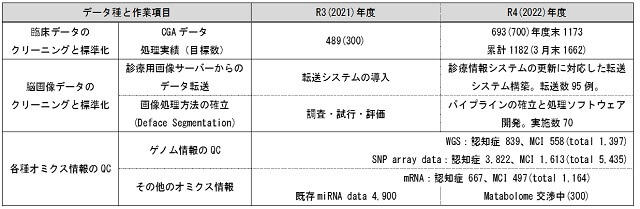
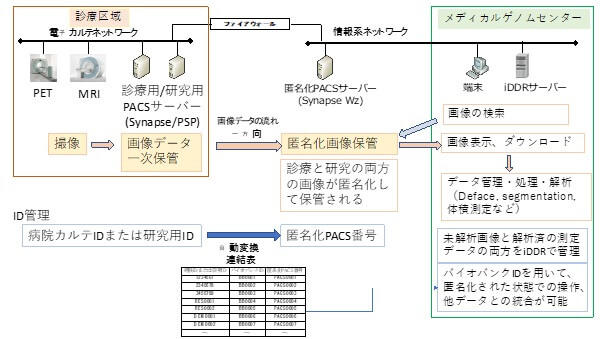
MRI等の脳画像データは医用画像の国際規格の一つであるDICOM※1形式で放射線科のPACS※2サーバーに保存されている。当該年度は、このデータをiDDRに転送するための仲介サーバー(匿名化PACSサーバー)を構築し、転送作業を進める予定であったが(図2参照)、コロナ禍とウクライナ戦争の影響で半導体が入手できず、システム導入は年度末となった。また、試験稼働(実データ転送は95例(表1))によりシステムのカスタマイズが必要と分かり、本格的なデータ転送は次年度に実施することとした。
一方、認知症/MCI症例のゲノム等のオミクス情報は、MGCデータサーバー格納前に全てクオリティーチェック(QC)を実施しており、データ品質は確保されていると考えられた。これまで認知症/MCI症の全ゲノム配列(WGS)データは1,397例、全ゲノムジェノタイピングデータは5,435例格納されている(表1)。前述のCGAデータの対象者(1,662例)と同一人物のWGSについては245例であるが、ジェノタイピングデータは1,376例をカバーしていることが確認できた。WGSのカバー数が少ないのは、認知症と診断された症例を優先して解析しているためで、今後MCI例のゲノム解析も進めていく予定である。
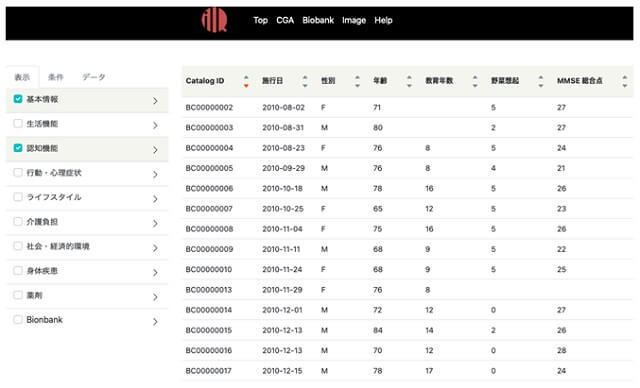
データベース構築においては、前年度は少数データを用いたdemo版を作製したが、今年度は一人当たり600項目を超えるCGAの実データをHTMLで表示・閲覧できるユーザーインターフェース構築を進めた。また、登録データの男女別総数や年齢別の分布などの要約情報が自動で可視化できるようにした(図3)。

トップページのメニューからCGAデータを選択すると、各種データの閲覧ページが開き、年齢や性別、MMSEのスコアなどを入力してデータを絞り込むことも可能で、研究者が利用したいデータを効率よく抽出することもできる(図4)。
一方、iDDRのセキュリティー対策も重要で、iDDRへのアクセスはセンター内でのみ可能とし、オリジナルデータの転送やコピーができないシステムとして構築を進めている。今後は、iDDRの利用申請の方法や利用ガイドラインなど、運用面のルール作りなどが必要となると考えている。
略語の説明
※1 DICOM:Digital Imaging and Communication in Medicine の略
※2 PACS:画像保存通信システム(Picture Archiving an Communication Systemsの略)
本研究開発への参加・協力部署
本研究は以下の部署が連携して推進しています。
- 国立長寿医療研究センター病院 もの忘れセンター
- 国立長寿医療研究センター病院 放射線診療部
- 国立長寿医療研究センター病院 先端医療開発推進センター医療情報室
- 国立長寿医療研究センター研究所 メディカルゲノムセンター
- 国立長寿医療研究センター研究所 脳機能画像診断開発部
- 国立長寿医療研究センター研究所 予防科学研究部
- 国立長寿医療研究センターバイオバンク
データベースを活用した実績
長寿科学研究者支援事業 指定課題研究について
本事業の詳細については以下のページをご覧ください。